데이터 꿈나무
[R] 내장 데이터 HistData의 Cholera 데이터로 분석하기(상관분석, 회귀분석, 다중공선성, 네트워크 플롯, 박스플롯) 본문
[R] 내장 데이터 HistData의 Cholera 데이터로 분석하기(상관분석, 회귀분석, 다중공선성, 네트워크 플롯, 박스플롯)
ye_ju 2023. 1. 24. 21:01안녕하세요~ 이번 포스팅은 R로 팀프로젝트를 했던 내용을 공유해드리려고 하는데요, R언어로 포스팅은 처음이네요ㅎㅎ 재미있게 봐주세요~!
📌 데이터 불러오기 및 구조 확인
library(HistData)
View(Cholera)
# Cholera 데이터 구조 확인
str(Cholera)
먼저 HistData를 불러온 후, Cholera 데이터의 구조를 살펴보았습니다.
데이터를 살펴보면 총 38개의 행과 15개의 변수로 이루어져 있음을 확인할 수 있습니다.
district 변수의 데이터 타입은 character형, region과 water 변수는 Factor 형으로 이루어져 있으며 나머지 변수는 integer, numeric으로 이루어져 있는 것을 확인할 수 있습니다.
📌 데이터 전처리
Cholera$region <- as.numeric(Cholera$region)
Cholera$water <- as.numeric(Cholera$water)Factor 형식의 region, water 변수를 numeric형으로 변환시켜주었습니다.
📌 상관분석(Correlation Analysis)
library(dplyr)
library(corrplot)
Cholera %>% select(-"district") %>%
cor(., ) %>% corrplot(., method = "number", order="AOE")문자형인 district 변수는 select 함수를 사용하여 제외시킨 후, corrplot함수를 이용하여 상관계수 행렬 시각화를 하였습니다.
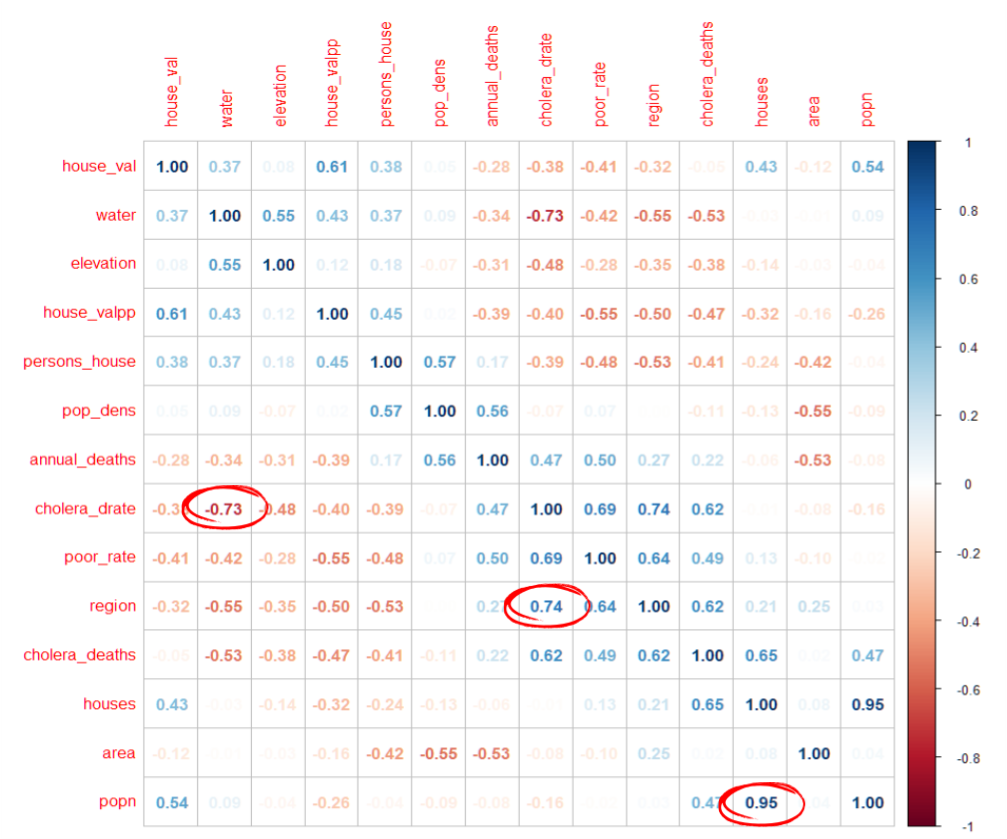
그 결과, 대부분의 값들이 약한 상관관계가 있는 것을 알 수 있었습니다. 또한 음의 상관관계를 가지는 변수들이 많은 것을 확인하였습니다.
cholera_drate와 water변수는 -0.73으로 강한 음의 상관관계를 가지고 있으며 cholera_drate와 region변수는 0.74로 강한 양의 상관관계를 가지고 있습니다. 따라서 인구 만명 당 콜레라 사망자 수는 급수지역과 런던지구 데이터와 관련이 있음을 확인하였습니다.
매우 강한 양의 상관관계를 보이는 변수는 0.95로 area와 popn변수입니다. 지역 데이터는 인구 수 데이터와 관련이 있음을 알 수 있습니다
📌 네트워크 플롯 (Network Plot)
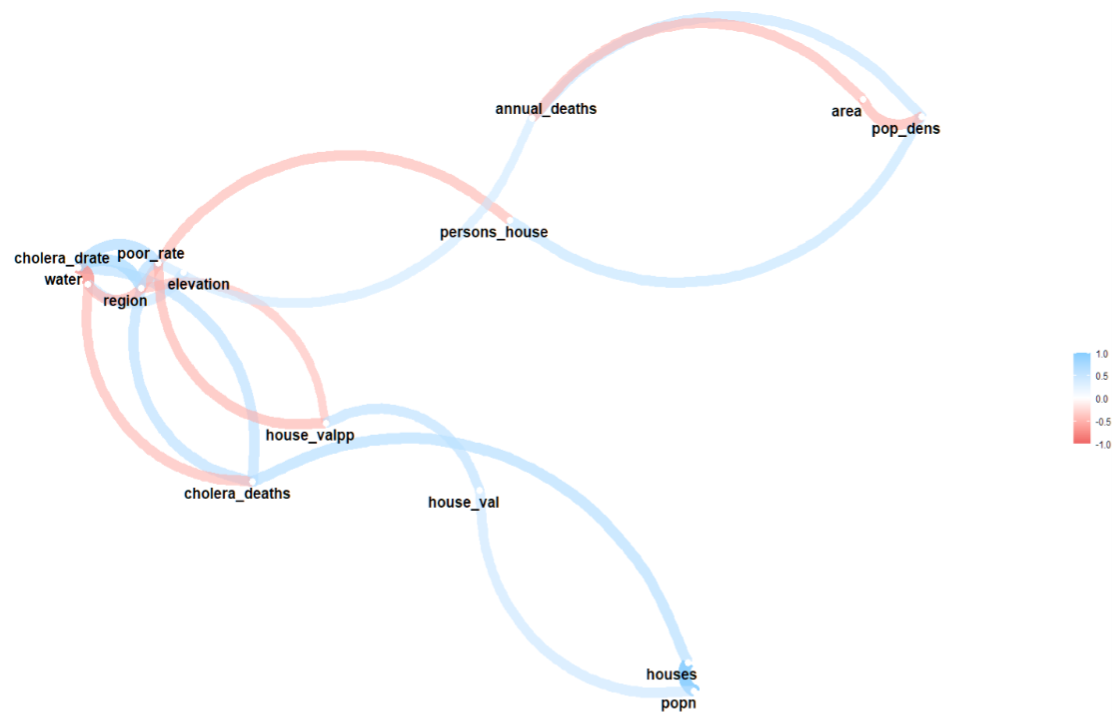
library(corrr)
dat <- Cholera %>% select(-"district")
correlate(dat) %>% network_plot(min_cor = 0.5)다음으로 network plot을 그려 상관분석 matrix를 시각화 한 후, 노드 수가 3개 이상인 변수들을 선정해 로지스틱 회귀분석을 진행할 것입니다.
📌 로지스틱 회귀분석 (Regression Analysis)
fit <- glm(cbind(cholera_deaths, popn) ~ water + elevation + poor_rate + house_valpp + area + pop_dens + region,
data=Cholera,
family = binomial)
library(car)
# 다중공선성 문제 확인
vif(fit)앞서 선정된 9개의 변수를 가지고 로지스틱 회귀분석을 진행하였습니다. 로지스틱 회귀분석은 종속변수가 범주형으로 0 또는 1인 경우 사용하는 회귀분석으로, cholera_deaths와 popn을 cbind로 묶어서 반응변수가 두가지 값만 가진다는 것을 의미합니다.
※ 다중공선성 문제
: 독립변수 X는 종속변수 Y하고만 상관관계가 있어야 하며, 독립변수 X들끼리 상관관계가 있어서는 안된다.


이때 설명변수들끼리 상관관계가 있으면 부정확한 회귀 결과가 도출될 수 있기 때문에 다중공선성 문제를 확인해보았습니다. 설명변수들의 값이 5보다 작게 나옴으로써 이 모델은 다중공선성 문제가 없다고 할 수 있습니다.
📌 변수 선택법(후진 제거법)
back <- step(fit, direction = "backward")
summary(back)
다중공선성 문제는 없지만 유의미한 변수를 선택하기 위해 유의하지 않은 변수를 제거하는 “후진제거법”을 진행하였습니다. summary함수로 확인한 결과, 변수들 water, elevation, poor_rate, area, region은 인구 10,000명당 콜레라 사망자 수와 인구수에 영향을 준다는 결과를 도출하였습니다.
따라서 0.05보다 작게 나오기 때문에 유의수준 0.05 이하에서는 귀무가설을 기각하고 대립가설을 채택합니다.
* 귀무가설 H0 : 두 집단이 차이가 없다.
* 대립가설 H1 : 두 집단이 차이가 있다.
📌 그래프 그리기
library(effects)
plot(allEffects(back))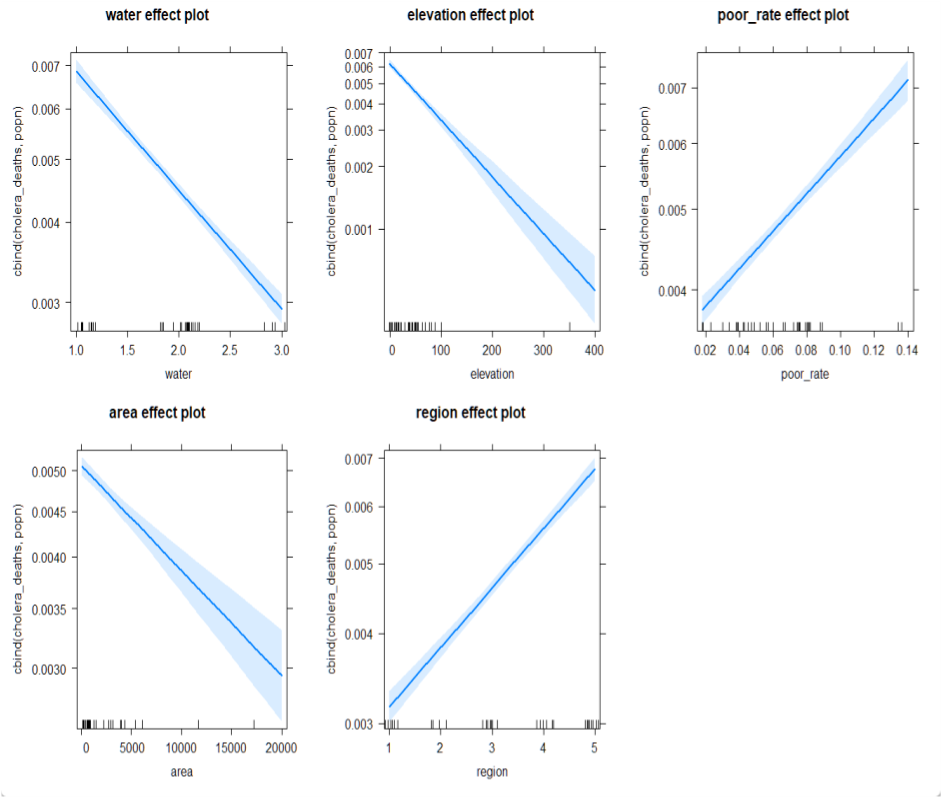
다음으로 반응변수 cholera_deaths, popn와 5개의 설명변수들 각각의 회귀 분석 결과를 시각화 하였습니다.
📌 모델의 특성 살펴보기
# coef() : 회귀 계수(절편과 기울기)를 보여주는 함수
# fitted() : 모델에 의하여 예측된 값을 구하는 함수
# residuals() : 실제값과 선형회귀모델로 구한 예측값의 차이인 잔차를 구하는 함수
# deviance() : 잔차 제곱합을 구하는 함수
coef(fit)
fitted(fit) # 모두 다 0에 가깝다.
residuals(fit)
deviance(fit)📌 추가 분석
library(ggpubr)
library(ggplot2)
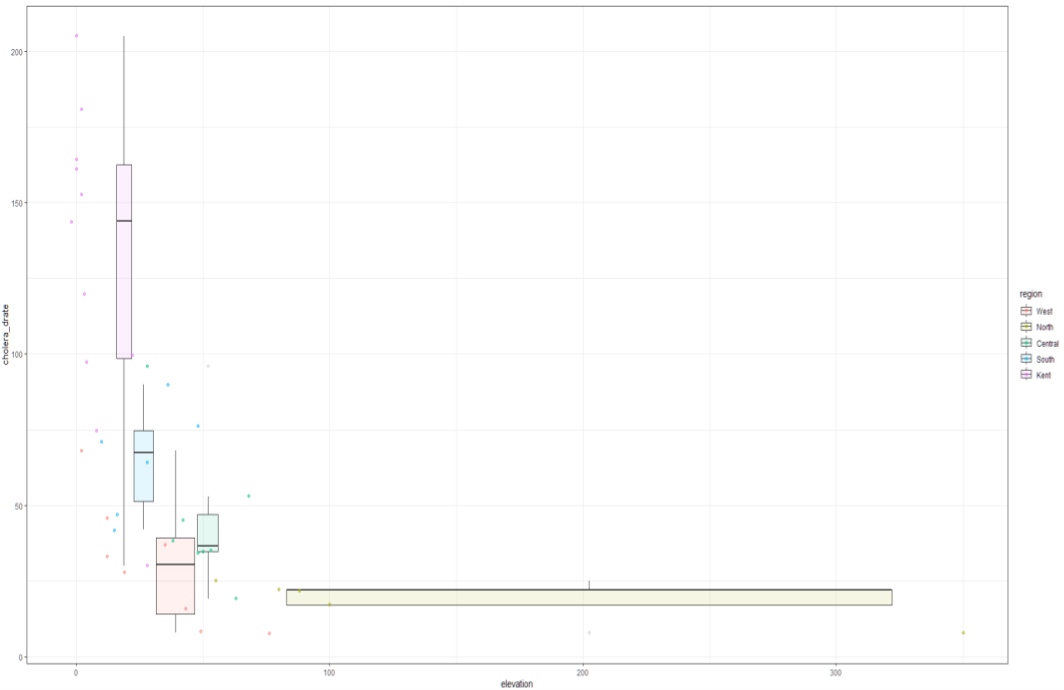
ggplot(data=Cholera, aes(elevation, cholera_drate)) +
geom_boxplot(alpha = 0.1, aes(elevation, fill=region)) +
geom_jitter(alpha = 0.5, aes(elevation, color=region), width=0.05) +
theme_bw()다음은 추가 분석입니다. 추가적으로 콜레라 질병이 고도와 관련이 있을 것이라고 추측한 후 ggplot함수를 통해 직접 시각화한 결과, 고도가 낮은 지역의 콜레라 사망자 수가 눈에 띄게 높은 것을 확인하였습니다.
고도가 낮은 지역에 물이 더 잘 고이기 때문에 낮은 고도에 있는 사람들이 오염된 물을 섭취하여 콜레라 사망자 수가 더 높은 것으로 나타났다는 결론을 내릴 수 있었습니다.