
데이터 꿈나무
[사전 학습] 1-1 데이터 선택 본문
데이터 선택
넘파이 실습
# 라이브러리 로딩
import numpy as np
# 파이썬 리스트에서 넘파이로 변환
a = [1, 3.14, True, 'hello'] # 리스트
b = np.array(a)
# 리스트 원소 데이터 타입 확인
print(a)
for element in a:
print('Data type of {} : {}'.format(element, type(element)))[1, 3.14, True, 'hello']
Data type of 1 : <class 'int'>
Data type of 3.14 : <class 'float'>
Data type of True : <class 'bool'>
Data type of hello : <class 'str'>
# 넘파이 배열 원소 확인
print(b)
for element in b:
print('Data type of {} : {}'.format(element, type(element)))['1' '3.14' 'True' 'hello']
Data type of 1 : <class 'numpy.str_'>
Data type of 3.14 : <class 'numpy.str_'>
Data type of True : <class 'numpy.str_'>
Data type of hello : <class 'numpy.str_'>
# 중첩 리스트 생성
a = [[1, 2, 3], [4, 5, 6]]
print(a)[[1, 2, 3], [4, 5, 6]]
type(a) # 출력: list# 중첩리스트를 넘파이 배열로 변환 --> 2차원인 행렬로 변환
b = np.array(a)
print(b)
type(b)[[1 2 3]
[4 5 6]]
# 배열(array)의 shape 확인
b.shape(2, 3)
# 배열의 차원 확인
b.ndim # 22
# 배열 내 총 원소 개수 확인
b.size6
# 2x3 행렬 -> 3x2 행렬
print(b.reshape(3, 2))[[1 2]
[3 4]
[5 6]]
# 배열 요소 데이터타입 변경 : 정수 -> 실수
b = np.array(a, dtype=np.float64)
print(b)[[1. 2. 3.]
[4. 5. 6.]]
# 배열 요소 데이터타입 변경 : 실수 -> 정수
b = b.astype(np.int64)
print(b)[[1 2 3]
[4 5 6]]
넘파이 배열 인덱싱
# 새로운 배열 arr 생성
arr = np.array([1, 2, 3, 4, 5])
print(arr)[1 2 3 4 5]
print(arr[0]) # 1
print(arr[3]) # 4
print(arr[-1]) # 5
2차원 배열 인덱싱
arr_2d = np.array([[1, 2, 3], [4, 5, 6]])
arr_2d[0, 0]1
arr_2d[1, 2]6
배열 슬라이싱
arr_2d = np.arange(1, 7).reshape(2, 3)
print(arr_2d)[[1 2 3]
[4 5 6]]
print(arr_2d[0, :])[1 2 3]
print(arr_2d[:, 2])[3 6]
print(arr_2d[:, :2])[[1 2]
[4 5]]
판다스 실습
import pandas as pd
data = {
'이름' : ['아이유', '김연아', '홍길동', '장범준', '강감찬'],
'학과' : ['국문학', '수학', '컴퓨터', '철학', '경영학'],
'성적' : [3.0, 1.0, 3.5, 2.7, 4.0]
}
data{'이름': ['아이유', '김연아', '홍길동', '장범준', '강감찬'],
'학과': ['국문학', '수학', '컴퓨터', '철학', '경영학'],
'성적': [3.0, 1.0, 3.5, 2.7, 4.0]}
# 딕셔너리 타입인 data를 pd.DataFrame() 인자로 넣어주면 됨
df = pd.DataFrame(data)
display(df)
📌 데이터 csv로 저장하기
df.to_csv('./data/student.csv', sep=',', index=False)📌 데이터 불러오기
df = pd.read_csv('./data/student.csv')
display(df)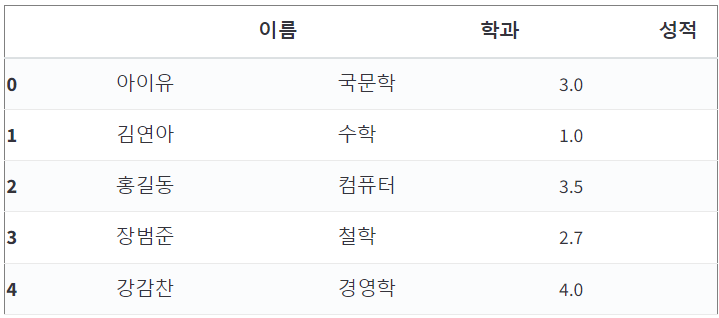
📌 판다스 원하는 데이터 선택하기
1) 슬라이싱(slicing)
df[1:5]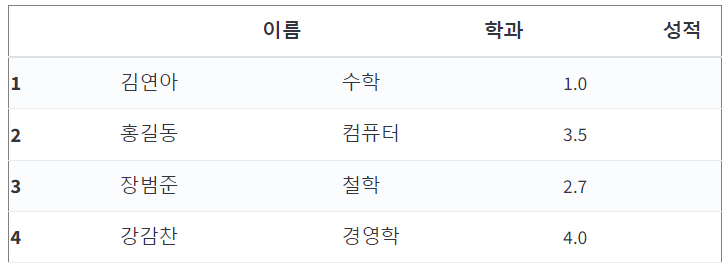
df[0:3]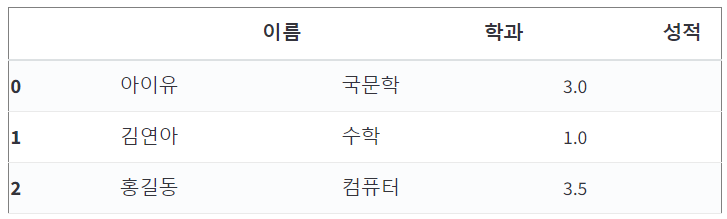
df[0:]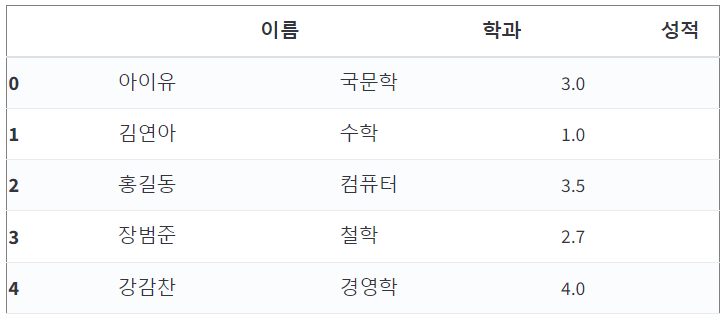
df[:]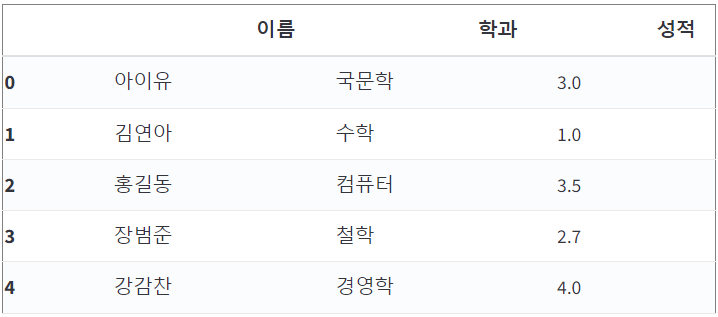
2) 인덱싱(indexing)
df[1] # key error가 뜬다.
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
~\miniconda3\envs\dx_env\lib\site-packages\pandas\core\indexes\base.py in get_loc(self, key, method, tolerance)
3360 try:
-> 3361 return self._engine.get_loc(casted_key)
3362 except KeyError as err:
~\miniconda3\envs\dx_env\lib\site-packages\pandas\_libs\index.pyx in pandas._libs.index.IndexEngine.get_loc()
~\miniconda3\envs\dx_env\lib\site-packages\pandas\_libs\index.pyx in pandas._libs.index.IndexEngine.get_loc()
pandas\_libs\hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item()
pandas\_libs\hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item()
KeyError: 1
The above exception was the direct cause of the following exception:
KeyError Traceback (most recent call last)
~\AppData\Local\Temp\ipykernel_4648\4061364927.py in <module>
----> 1 df[1] # key error가 뜬다
~\miniconda3\envs\dx_env\lib\site-packages\pandas\core\frame.py in __getitem__(self, key)
3456 if self.columns.nlevels > 1:
3457 return self._getitem_multilevel(key)
-> 3458 indexer = self.columns.get_loc(key)
3459 if is_integer(indexer):
3460 indexer = [indexer]
~\miniconda3\envs\dx_env\lib\site-packages\pandas\core\indexes\base.py in get_loc(self, key, method, tolerance)
3361 return self._engine.get_loc(casted_key)
3362 except KeyError as err:
-> 3363 raise KeyError(key) from err
3364
3365 if is_scalar(key) and isna(key) and not self.hasnans:
KeyError: 1
df['이름']0 아이유
1 김연아
2 홍길동
3 장범준
4 강감찬
Name: 이름, dtype: object
df['학과']0 국문학
1 수학
2 컴퓨터
3 철학
4 경영학
Name: 학과, dtype: object
3) Fancy Indexing
df[['이름', '학과']]
fancy_list = ['이름', '학과']
df[fancy_list]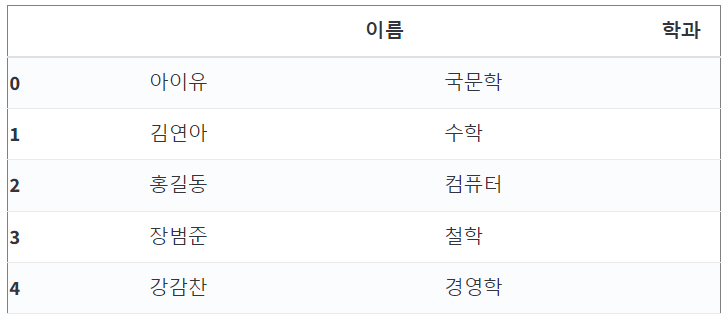
4) 슬라이싱 + 인덱싱
df[1:3][['학과', '이름']]
df[['학과', '이름']][1:3]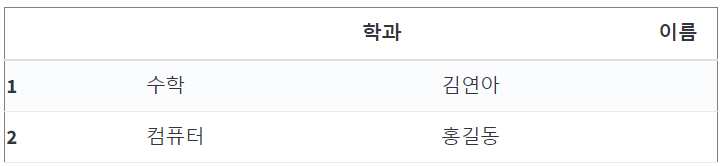
5) Boolean indexing
연산자를 이용하여 인덱싱 수행 (e.g. ==, !=, >, etc)
df[df['학과'] == '수학']
df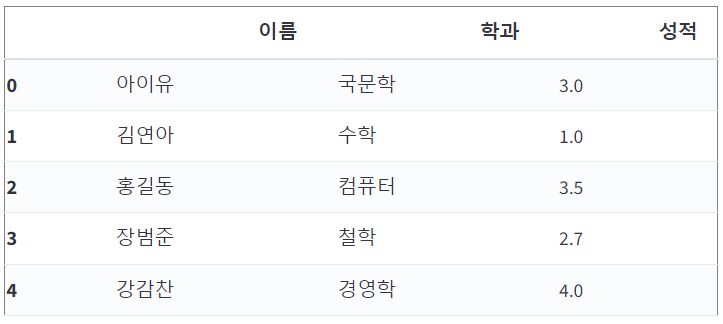
df [df['성적'] % 0.5 == 0]
df['성적'] % 0.5 == 00 True
1 True
2 True
3 False
4 True
Name: 성적, dtype: bool
6) pandas 고급 인덱싱 loc % iloc 인덱서
df.loc[3]이름 장범준
학과 철학
성적 2.7
Name: 3, dtype: object
df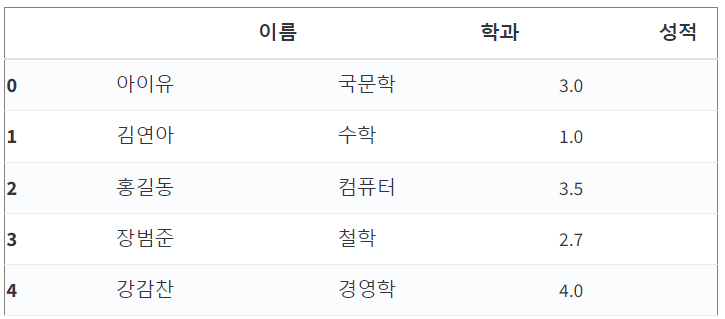
df.loc[[1, 3, 4]]
df.loc[ [1, 3, 4], :]
df.loc[ [1, 3, 4], '이름':'성적']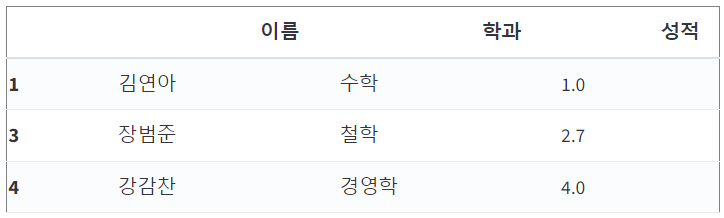
df.loc[ [1, 3, 4], '이름':'학과']
df.loc[ [1, 3, 4], ['이름','학과']]
df.iloc[[1, 3, 4], 0:2]
# loc + boolean indexing
df.loc[ df['성적'] % 2 != 0, ['이름', '학과', '성적']]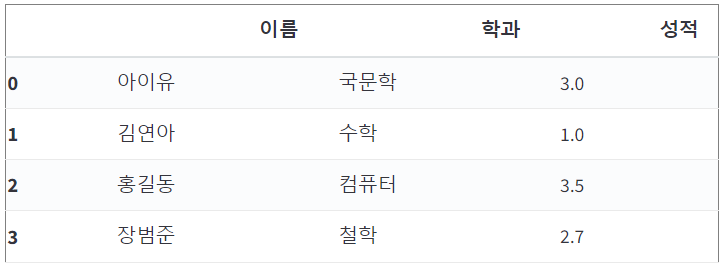
df.loc[ df['성적'] % 2 != 0, ['이름', '성적']]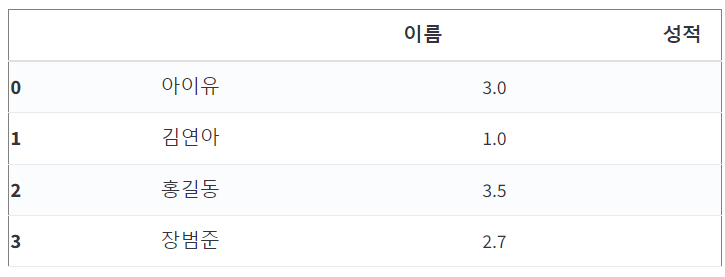
'Activity > KT AIVLE' 카테고리의 다른 글
| [사전 학습] 1-3 데이터 합치기 (3) | 2024.08.31 |
|---|---|
| [사전학습] 1-2 데이터 변경 (0) | 2024.08.31 |

