
데이터 꿈나무
[데이터 청년 캠퍼스] CNN의 ResNet50 모델로 스타벅스 음료 이미지 분류 모델 구현 with Python 본문
[데이터 청년 캠퍼스] CNN의 ResNet50 모델로 스타벅스 음료 이미지 분류 모델 구현 with Python
ye_ju 2022. 12. 25. 00:00안녕하세요~ 저번 포스팅은 CNN의 VGG16 모델로 이미지 분류 모델을 구현해봤는데요, 이번 포스팅에서는 VGG16이 아닌 ResNet50 모델로 모델을 구현해보려고 해요..! 이전 포스팅이 궁금하신 꿈나무들은 아래 링크를 클릭해주세요~
[데이터 청년 캠퍼스] CNN을 이용한 모델링(VGG16 모델) / 스타벅스 이미지 분류 모델
안녕하세요~ 이번 포스팅은 저번 포스팅에 이어서 본격적으로 CNN의 VGG16 모델을 적용하여 이미지 분류 모델을 구현해보려고 해요~! 저번 포스팅은 모델링 전에 거쳐야 할 단계인 이미지 사이즈
risingdata.tistory.com
여러 모델을 구현해보고 가장 성능이 좋은 모델이 무엇인지 해봤는데 ResNet50 모델이 성능이 가장 좋게 나오더라고요~!
먼저 전체적인 모델링 과정부터 살펴볼게요!
전체적인 모델링 과정
크롤링을 통해 음료별 평균 287장 정도의 데이터를 수집하여 train, validation, test 데이터 셋을 4:3:3으로 나누어 모델을 학습하였습니다. input image size는 256X256이며, 스타벅스 top10 메뉴 10개를 분류하는 모델을 개발했습니다.
Resnet50 transferlearning을 이용한 모델의 구조와 사용된 parameter들은 아래 표와 같습니다.
| Input size | 256, 256, 3 | Learning rate | 0.005 |
| Activation function | ReLU / Softmax | Loss function | categorical_crossentropy |
| Epoch | 30 | Pooling | MaxPooling2D (2, 2) |
| Batch size | 64 | Dense layer | 512 - 256 - 10 |
| Optimizer | Adam |
각 parameter는 multiable image classification 에 가장 최적인 값으로 구성하였습니다.
ResNet50의 convolution layer 전체를 freezing한 상태로, flatten layer 뒤의 output이 10 종류의 음료 이미지 classification이 가능하도록 layer를 쌓아주었습니다. Layer마다의 Activation function은 ReLU를 기본적으로 사용했으며, Output classification을 위한 함수로는 softmax를 사용하여 0부터 9사이의 label을 예측합니다.
분류모델의 최종 test 성능은 accuracy 0.76, AUC 0.86으로 나왔습니다.
📌 모듈 불러오기 및 설치
※ 참고) 모듈이 없을 경우,
!pip install [모듈 이름]
import os
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
import argparse
import easydict
from time import sleep
from IPython.display import clear_output
from keras.preprocessing.image import ImageDataGenerator
from keras.layers import Dropout
from keras.layers import Flatten
from keras.layers import Dense
from keras.layers import Input
from keras.layers import MaxPooling2D
from keras.layers import AveragePooling2D
from keras.layers import BatchNormalization
from keras.models import Model
from tensorflow.keras.optimizers import Adam
from keras.metrics import AUC
from sklearn.metrics import roc_curve, auc, roc_auc_score
from keras.applications.resnet_v2 import ResNet50V2, ResNet101V2, ResNet152V2, preprocess_input, decode_predictions
from keras.applications.resnet import ResNet50, preprocess_input, decode_predictions
from sklearn.preprocessing import LabelBinarizer
from sklearn.metrics import confusion_matrix, classification_report, multilabel_confusion_matrix
from keras.models import load_model
📌파일 경로 설정
- DIR 변수에 경로 설정
import os
DIR = "C:/Users/YeChoi/Downloads/model_submit/"
data_DIR = DIR + "/model_image"
os.listdir(data_DIR + "/image_file")
📌 이미지 정리
- 메뉴별 데이터 수 확인
import os
file_path = data_DIR + "/image_file/"
file_names = os.listdir(file_path)
print("메뉴 개수: ", len(file_names), "개")
print("\n========== 메뉴별 음료 사진 개수 확인하기 ==========\n")
for coffee in file_names:
PATH = file_path + coffee
print(str(coffee), " : ", str(len(os.listdir(PATH))))
📌 이미지 형식 확인
- .png, .jpg 파일 형식만 남기기
from pathlib import Path
import imghdr
from PIL import Image
image_extensions = [".png", ".jpg"] # add there all your images file extensions
img_type_accepted_by_tf = ["bmp", "gif", "jpeg", "png"]
# eeeeeeeee
PATH = data_DIR+'/split_image'
# 에러나는 파일이 무엇인지 확인하기 위해 빈 리스트
none_image = []
webp_image = []
for filepath in Path(PATH).rglob("*"):
if filepath.suffix.lower() in image_extensions:
img_type = imghdr.what(filepath)
if img_type is None:
print(f"{filepath} is not an image")
none_image.append(str(filepath))
# 이미지 파일이 아닌 것은 삭제
# https://codechacha.com/ko/python-delete-file-and-dir/
# os.remove(str(filepath))
elif img_type not in img_type_accepted_by_tf:
print(f"{filepath} is a {img_type}, not accepted by TensorFlow")
webp_image.append(str(filepath))
# 이미지 형식이 잘못된 것은 jpeg 형식으로 전환
im = Image.open(filepath).convert("RGB")
im.save(images, "jpeg")
# 이미지 webp 파일 경로 확인
from pprint import pprint
pprint(webp_image)[]
📌 Train, Test 데이터셋 나누기
- 메뉴별 데이터 수 확인
# 메뉴별 데이터 수
import os
file_path = data_DIR + "/split_image/"
file_names = os.listdir(file_path)
for data in file_names:
PATH = file_path + data
coffee_files = os.listdir(PATH)
print("[", str(data), "data ]\n")
for coffee in coffee_files:
PATH_detail = os.path.join(PATH, coffee)
print(str(coffee), " : ", str(len(os.listdir(PATH_detail))))
print("\n======================================================================\n")
📌 이미지 전처리
- 데이터셋 구축
# 데이터셋 구축
from keras.preprocessing.image import ImageDataGenerator
TRAIN_PATH = data_DIR + "/split_image/train"
VAL_PATH = data_DIR + "/split_image/val"
TEST_PATH = data_DIR + "/split_image/test"
MODEL_PATH = DIR
BATCH_SIZE = 64 # 처음 size 50
IMG_HEIGHT = 256
IMG_WIDTH = 256
trainGen = ImageDataGenerator(
rescale = 1./255, #, # 값을 0과 1 사이로 변경
rotation_range = 30, # 무작위 회전각도 30도 이내
# shear_range = 0.2, # 층밀리기 강도 20% (정사각형 -> 평행사변형)
# zoom_range = 0.2, # 무작위 줌 범위 20%
horizontal_flip = True # 무작위로 가로로 뒤짚는다.
)
valGen = ImageDataGenerator(
rescale = 1./255#,
# rotation_range = 30,
# shear_range = 0.2,
# zoom_range = 0.2,
# horizontal_flip = True
)
testGen = ImageDataGenerator(
rescale = 1./255#,
# rotation_range = 30,
# shear_range = 0.2,
# zoom_range = 0.2,
# horizontal_flip = True
)
train_generator = trainGen.flow_from_directory(
TRAIN_PATH,
class_mode = "categorical",
target_size = (IMG_HEIGHT, IMG_WIDTH),
shuffle = True,
batch_size = BATCH_SIZE)
# initialize the validation generator
validation_generator = valGen.flow_from_directory(
VAL_PATH,
class_mode = "categorical",
target_size = (IMG_HEIGHT, IMG_WIDTH),
shuffle = True,
batch_size = BATCH_SIZE)
# initialize the testing generator
test_generator = testGen.flow_from_directory(
TEST_PATH,
class_mode = "categorical",
target_size = (IMG_HEIGHT, IMG_WIDTH),
shuffle = False,
batch_size = BATCH_SIZE)
- 이미지 확인
import matplotlib.pyplot as plt
# 이미지 확인하기 (2장가량)
for _ in range(2):
img, label = train_generator.next()
print(img.shape) # (1,256,256,3)
# print(label)
plt.imshow(img[0])
plt.show()
labels = validation_generator.classes
# print(labels)
📌 모델 생성 및 예측
from keras.layers import AveragePooling2D
from keras.layers import Dropout
from keras.layers import Flatten
from keras.layers import Dense
from keras.layers import Input
from keras.layers import MaxPooling2D
from keras.layers import BatchNormalization
from keras.models import Model
from tensorflow.keras.optimizers import Adam
from sklearn.metrics import classification_report
import matplotlib.pyplot as plt
import numpy as np
import argparse
from keras.metrics import AUC
from keras.applications.resnet_v2 import ResNet50V2, ResNet101V2, ResNet152V2, preprocess_input, decode_predictions
from keras.applications.resnet import ResNet50, preprocess_input, decode_predictionsresnet = ResNet50V2(include_top = False, # 맨 마지막 분류 layer 제거
weights = 'imagenet', # 가중치: imagenet
input_shape = (256,256,3))
# 기존 학습된 layer들을 freazing
for layer in resnet.layers:
layer.trainable = False
x = resnet.output
x = MaxPooling2D(pool_size = (2, 2))(x)
x = Flatten()(x)
x = Dropout(0.8)(x) # 기존 초기 Dropout = 0.5
x = Dense(512, activation = 'relu', input_dim = (256,256,3))(x)
x = BatchNormalization()(x)
x = Dense(256, activation = 'relu')(x)
x = BatchNormalization()(x)
x = Dense(10, activation = 'softmax')(x)
model = Model(inputs = resnet.input, outputs = x)ResNet50 모델을 사용하여 include_top은 False로 두어 top layer는 포함하지 않게 설정하였습니다. 그리고 가중치를 imagenet으로두었습니다.
기존 학습된 layer들을 freezing 하였습니다.
N_EPOCH = 30
LR = 0.005 # 처음 lr = 0.05, 두번째 lr = 0.01
# compile the model
opt = Adam(learning_rate = LR, decay = LR / N_EPOCH)
model.compile(loss = "categorical_crossentropy", optimizer = opt,
metrics = ["accuracy", AUC(multi_label = True, num_labels = 10, name = 'AUC')])
H = model.fit_generator(
train_generator,
steps_per_epoch = train_generator.samples // BATCH_SIZE,
epochs = N_EPOCH,
validation_data = validation_generator,
validation_steps = validation_generator.samples // BATCH_SIZE)에폭은 30, Learning Rate는 처음은 0.005로 설정해주었습니다.
모델의 성능을 높이려면 적당한 최적화 기법을 사용해야 하는데요, 저는 여기에서 Adam 기법을 사용하였습니다.
Loss Function은 categorical_crossentropy 으로 해주었습니다.
에폭을 돌리면서 학습한 결과는 아래와 같습니다.


성능 accuracy 0.9049, AUC 0.9946이 나온 것을 확인할 수 있습니다.
train_generator.samples # 1147
📌 Training, Validation accuracy 그래프 그리기
import easydict
args = easydict.EasyDict({
"plot" : 'accuracy.png',
})
N = N_EPOCH
plt.style.use("ggplot")
plt.figure()
# plt.plot(np.arange(0, N), H.history["loss"], label="train_loss")
# plt.plot(np.arange(0, N), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, N), H.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, N), H.history["val_accuracy"], label="val_acc")
# plt.plot(np.arange(0, N), H.history["AUC"], label="train_AUC")
# plt.plot(np.arange(0, N), H.history["val_AUC"], label="val_AUC")
plt.title("Training Accuracy on Dataset \nlearning rate = 0.005, batch size = 64, epoch = 30 \nonly train set augmentation: rotation, horizontal_filp")
plt.xlabel("Epoch #")
plt.ylabel("Accuracy")
plt.legend(loc = "lower left")
plt.savefig(args["plot"])
train과 validation 성능이 비슷하게 올라가는 것을 보면 과적합이 일어나지 않고 있다는 사실을 알 수 있습니다.
📌 Training, Validation accuracy AUC 그래프 그리기
import easydict
args = easydict.EasyDict({
"plot" : 'auc.png',
})
N = N_EPOCH
plt.style.use("ggplot")
plt.plot(np.arange(0, N), H.history["AUC"], label = "train_AUC")
plt.plot(np.arange(0, N), H.history["val_AUC"], label = "val_AUC")
plt.title("Training AUC on Dataset \nlearning rate = 0.005, batch size = 64, epoch = 30 \nonly train set naugmentation: rotation, horizontal_filp")
plt.xlabel("Epoch #")
plt.ylabel("AUC")
plt.legend(loc = "lower left")
plt.savefig(args["plot"])
AUC도 마찬가지로 train과 validation 성능의 차가 크지 않아 과적합이 일어나지 않고 잘 예측을 하고 있다는 사실을 알 수 있습니다.
📌 모델 저장하기
print("[INFO] saving model...")
model.save(DIR + "/ResNet50V2_model_final_cate", save_format = "h5")[INFO] saving model . . .
📌 저장된 모델 불러와서 성능 확인
print("[INFO] loading model...")
from keras.models import load_model
reconstructed_model = load_model(DIR + "/ResNet50V2_model_final_cate")
reconstructed_model.summary()
- validation 성능 확인
loss, accuracy, AUC = reconstructed_model.evaluate_generator(validation_generator,
steps = validation_generator.samples // BATCH_SIZE + 1)
print('Validation accuracy :', accuracy)
print('Validation AUC :',AUC)
- test 성능 확인
test_generator.classes # test data class 목록 확인
# test data class 이름 확인 -> target 변수에 지정
test_generator.class_indices.keys()
📌 multilabel_confusion_matrix 로 ROC AUC curve 확인하기
from sklearn.metrics import multilabel_confusion_matrix
Y_pred = reconstructed_model.predict_generator(test_generator,
test_generator.samples // BATCH_SIZE + 1)
y_pred = np.argmax(Y_pred, axis = 1)
y_test = test_generator.classes
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelBinarizer
from sklearn.metrics import roc_curve, auc, roc_auc_score
target= ['Cold_Brew_or_Iced_Caffe_Americano_or_Iced_Coffee',
'Iced_Caffe_Latte_or_Dolce_Cold_Brew_or_Iced_Starbucks_Dolce_Latte',
'Iced_Caramel_Macchiato', 'Iced_Grapefruit_Honey_Black_Tea',
'Iced_Malcha_Latte_from_Jeju_Organic_Farm', 'Iced_Mango_Passion_Fruit_Blended',
'Iced_Mint_Chocolate_Chip_Blended', 'Iced_Strawberry_Delight_Yogurt_Blended',
'Java_Chip_Frappuccino', 'Vanila_Cream_Cold_Brew']
# set plot figure size
fig, c_ax = plt.subplots(1,1, figsize = (12, 8))
# function for scoring roc auc score for multi-class
def multiclass_roc_auc_score(y_test, y_pred, average = "macro"):
lb = LabelBinarizer()
lb.fit(y_test)
y_test = lb.transform(y_test)
y_pred = lb.transform(y_pred)
for (idx, c_label) in enumerate(target):
fpr, tpr, thresholds = roc_curve(y_test[:,idx].astype(int), y_pred[:,idx])
c_ax.plot(fpr, tpr, label = '%s (AUC:%0.2f)' % (c_label, auc(fpr, tpr)))
c_ax.plot(fpr, fpr, 'b-', label = 'Random Guessing')
return roc_auc_score(y_test, y_pred, average = average)
print('ROC AUC score:', multiclass_roc_auc_score(y_test, y_pred))
import easydict
args = easydict.EasyDict({
"plot" : 'ROC AUC curve.png',
})
c_ax.legend()
c_ax.set_xlabel('False Positive Rate')
c_ax.set_ylabel('True Positive Rate')
plt.title("ROC AUC curve \nlearning rate = 0.005, batch size = 64, epoch = 30 \nonly train set naugmentation: rotation, horizontal_filp")
plt.show()
plt.savefig(args["plot"])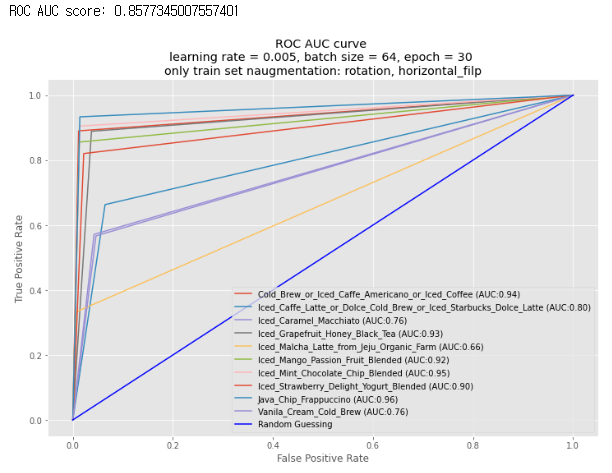
📌 메뉴별 성적 확인
from sklearn.metrics import confusion_matrix, classification_report
print('Confusion Matrix')
print(confusion_matrix(test_generator.classes, y_pred))
print('Classification Report')
# target_names = ['Cats', 'Dogs', 'Horse']
print(classification_report(test_generator.classes, y_pred,
target_names = test_generator.class_indices.keys()))
📌 confusion matrix 그리기
import seaborn as sns
y_test = test_generator.classes
cmat = confusion_matrix(y_test, y_pred)
plt.figure(figsize = (10,10))
# label =[0,1,2,3,4,5,6,7,8,9]
label = ['Cold_Brew_or_Iced_Caffe_Americano_or_Iced_Coffee',
'Iced_Caffe_Latte_or_Dolce_Cold_Brew_or_Iced_Starbucks_Dolce_Latte',
'Iced_Caramel_Macchiato', 'Iced_Grapefruit_Honey_Black_Tea',
'Iced_Malcha_Latte_from_Jeju_Organic_Farm', 'Iced_Mango_Passion_Fruit_Blended',
'Iced_Mint_Chocolate_Chip_Blended', 'Iced_Strawberry_Delight_Yogurt_Blended',
'Java_Chip_Frappuccino', 'Vanila_Cream_Cold_Brew']
import easydict
args = easydict.EasyDict({
"plot" : 'confusion matrix.png',
})
sns.heatmap(cmat, annot = True, cbar = False, cmap = 'Paired',
fmt = "d", xticklabels = label, yticklabels = label);
plt.title("confusion matrix \nlearning rate = 0.005, batch size = 64, epoch = 30 \nonly train set naugmentation: rotation, horizontal_filp")
plt.show()
plt.savefig(args["plot"])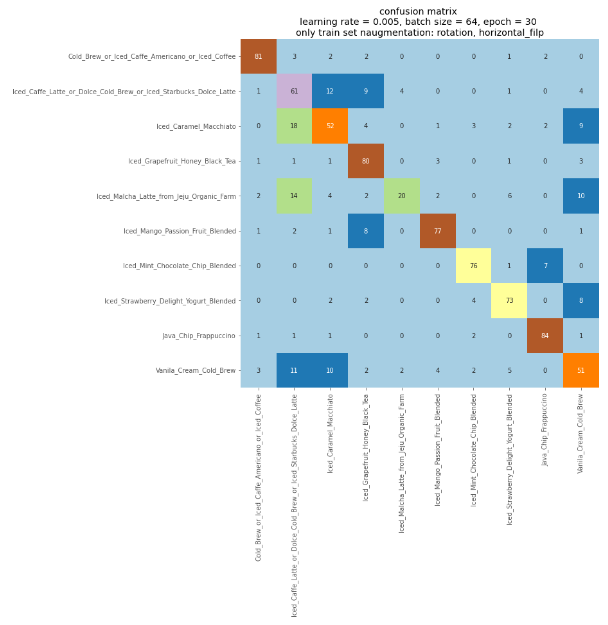
📌 predict 데이터로 예측이 잘 되는지 시각화
import os
predict_path = data_DIR +"/predict_image"
predict_images = os.listdir(predict_path)
predict_images
import matplotlib.pyplot as plt
from IPython.display import clear_output
from time import sleep
# predict_images에서 랜덤으로 하나의 이미지를 가져옴
# random.seed(128) # 실제로는 계속 바꿔줄 수 있음
# random_number = random.randrange(0, 10)
for i in range(10):
# 적용해볼 이미지
predict_image_path = predict_path + "/" + predict_images[i]
# 이미지 resize
img = Image.open(predict_image_path)
img = img.convert("RGB")
img = img.resize((256, 256))
data = np.asarray(img)
X = np.array(data)
X = X.astype("float") / 255
X = X.reshape(1, 256, 256,3)
# 예측
pred = reconstructed_model.predict(X)
result = [np.argmax(value) for value in pred] # 예측 값중 가장 높은 클래스 반환
print("음료 사진의 실제 카테고리 : ", predict_images[i].replace("_predict.jpg", ""))
print('음료 사진의 분류된 카테고리 : ', label[result[0]])
# 이미지 확인하기
plt.imshow(img)
plt.show()
sleep(2)
clear_output(wait=True)
음..ㅎㅎ 멋있게 맞추는 결과를 보여드리고 싶었는데 틀려버렸네요ㅎ..
이상으로 ResNet50 모델로 이미지 분류모델을 만들어보는 포스팅을 마치겠습니다. 긴 글 읽어주셔서 감사합니다:)

'Activity > 데이터 청년 캠퍼스' 카테고리의 다른 글
| [데이터 청년 캠퍼스] CNN을 이용한 모델링(VGG16 모델) / 스타벅스 이미지 분류 모델 (2) | 2022.12.24 |
|---|---|
| [데이터 청년 캠퍼스] 딥러닝 VGG16 모델 구현 이미지 전처리 with Python (0) | 2022.12.23 |
| [데이터 청년 캠퍼스] 구글 이미지 자동 스크롤 웹크롤링 with Python (4) | 2022.09.29 |
| [데이터 청년 캠퍼스] 네이버 자동 스크롤 이미지 크롤링 with 파이썬(Python) (2) | 2022.09.25 |
| [데이터 청년 캠퍼스] Python 스타벅스 메뉴 영양성분 크롤링 (2) | 2022.09.17 |


