
데이터 꿈나무
[데이터 청년 캠퍼스] 네이버 자동 스크롤 이미지 크롤링 with 파이썬(Python) 본문
안녕하세요~! 저번 방학 때 대외활동 '데이터 청년 캠퍼스'에서 팀원들과 프로젝트를 하면서 네이버 자동 스르롤 이미지 크롤링을 해봤었는데요, 그때 작성한 코드 공유해드리려고 해요~
제가 이번 프로젝트에서 스타벅스 음료 이미지를 크롤링한 이유는 이미지 분류 모델에 쓰기 위해서 인데요, 아마도 다다음 포스팅에는 딥러닝 VGG모델 글이 업로드 될 예정입니다!! 많이 기대해주세요:)
우선 앞부분은 저번 포스팅 글이랑 거의 똑같아서 설명도 똑같이 작성하였지만 좀 더 상세한 설명이 필요하신 분들은 아래 링크를 타고 저번 글을 봐주시면 감사하겠습니다!
https://risingdata.tistory.com/2?category=1069489
[데이터 청년 캠퍼스] Python 스타벅스 메뉴 영양성분 크롤링
안녕하세요:) 첫번째 게시물은 크롤링으로 시작하려고 합니다. 데이터 청년 캠퍼스라는 대외활동 과정을 통해서 카페 메뉴 및 영양성분을 크롤링 해보는 경험을 가졌었는데요, 프로젝트 활동을
risingdata.tistory.com
필요한 모듈 임포트
우선 크롤링을 하기 위한 모듈을 불러와야 합니다.
해당 모듈이 없을 시에 오류가 뜨게 되는데, 이는 아래의 주석과 같이 'pip install 모듈이름' 을 해주어 모듈을 설치해주면 됩니다.
import urllib.request
from urllib.request import urlopen
from bs4 import BeautifulSoup
from selenium import webdriver
# 웹 애플리케이션의 테스트를 자동화하기 위한 프레임워크
# 손으로 마우스를 클릭해서 데이터를 검색하고 스크롤링 할 수 있다
from selenium.webdriver.common.keys import Keys
# 중간마다 sleep을 걸어야 함
import time
from pprint import pprint
웹 드라이버 열기(스타벅스 음료 메뉴 창)
다음으로는 webdriver를 실행시켜주어야 합니다. webdriver를 실행시켜주려면 Chrome의 webdriver를 설치해준 후 해당 코드를 작성하는 파일에 webdriver가 있어야 실행이 됩니다.
저는 스타벅스의 음료 메뉴가 있는 홈페이지 주소를 가져와서 webdriver를 실행시켜주었습니다.
driver = webdriver.Chrome()
driver.get("https://www.starbucks.co.kr/menu/drink_list.do")
html_source = driver.page_source
soup = BeautifulSoup(html_source, "html.parser")
그 후 제품 코드와 제품 이름만 따로 불러와서 prod_cd에 저장해주었습니다.
prod속성 값과 'img태그의 'alt'값을 추출하였습니다.
products = soup.select(".product_list dd a")
product_code = [[product["prod"], product.find("img")["alt"]] for product in products]
# pprint(product_code)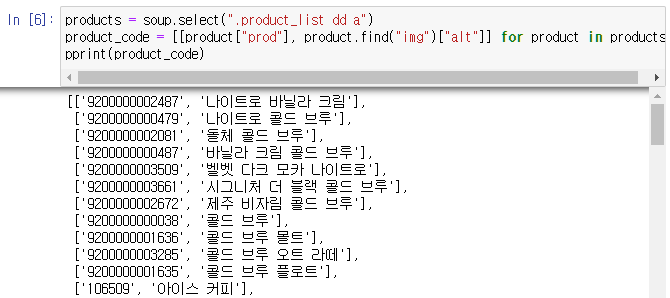
개수를 확인해보니 137개의 메뉴가 있는 것을 확인할 수 있었습니다.
print(len(product_code))
# 결과 137하지만 실제로 음료 메뉴 개수를 보니 전체 메뉴는 134개인데, 마지막에 시즌한정 메뉴가 겹쳐나오는 현상이 발생하였습니다. 그래서 해당 메뉴들 duplication은 index로 수기 지정하기로 결정하였습니다.
# 무슨 값이 들어있는지 확인
product_code[134:137]
# 삭제
del product_code[134:137]
del product_code[67]
# 삭제된 것을 확인할 수 있음
pprint(product_code)
참고로 remove, pop, del의 차이점이 무엇인지 아래 접은글에 작성해놓았으니 참고해주세요~
remove()
remove()는 지우고자 하는 인덱스가 아닌, 값을 입력하는 방식입니다. 만약 지우고자 하는 값이 리스트 내에 2개 이상이 있다면 순서상 가장 앞에 있는 값을 지우게 됩니다. 해당 값을 삭제 후, 리스트를 재조정합니다.
pop(), del
pop()과 del은 지우고자 하는 리스트의 인덱스를 받아서 지우는 방식입니다. 두 개의 차이는 pop()은 지워진 인덱스의 값을 반환하지만 del은 반환하지 않습니다. 이 차이 때문에 미세하게 del이 pop()보다 수행속도가 더 빠릅니다. 또한 remove()와 동일하게 pop()과 del은 특정 인덱스를 삭제한 다음, 리스트를 재조정합니다.
스타벅스 음료 한글, 영어 이름 둘 다 크롤링
스타벅스 음료의 코드, 한글, 영어 이름을 크롤링 하여 각각 code, name, name_en 변수에 넣어주었습니다.
그리고 트래픽 조절을 위해 3초간 pause하였습니다.
import time
# result를 담을 빈 List 생성
result = []
# 제품별로 for loop
for prod in product_code:
container = dict()
code = prod[0]
name = prod[1]
driver.get("https://www.starbucks.co.kr/menu/drink_view.do?product_cd={product_code}".format(product_code = code))
html_source = driver.page_source
soup = BeautifulSoup(html_source, "html.parser")
# 영어 이름 크롤링
name_en = soup.select_one("div.myAssignZone h4 span").get_text()
container['code'] = code
container['name'] = name
container['name_en'] = name_en
result.append(container)
# 트래픽 조절을 위해 3초간 pause
time.sleep(3)
pprint(result)
크롤링으로 가져온 데이터를 csv 파일로 저장
그 후 크롤링으로 가져온 데이터를 csv파일로 저장해 주었습니다.
import pandas as pd
df = pd.DataFrame(result)
df.to_csv('./starbucks_english.csv', index = False, encoding="utf-8-sig")
저희는 이미지 분류 모델에 쓸 이미지를 크롤링하고 있는데요, 이미지 분류를 할 때 HOT메뉴는 컵이 불투명하여 음료를 분류하는데에 어려움이 있을 것 같다는 판단에 ICED음료만 크롤링 해오기로 했습니다.
그래서 위에서 저장한 csv 파일을 ICED로 필터링 해주겠습니다.
csv 파일 확인 및 starbucks_name에 저장
ICED만 필터링 해주기 위해 csv 파일을 starbucks_name 변수에 저장해주도록 하겠습니다.
starbucks_name = pd.read_csv("./starbucks_english.csv")
starbucks_name
starbucks_name.info() # df의 열구조 확인
ICED만 필터링
# https://yganalyst.github.io/data_handling/Pd_11/
## req에 ICED만 추출할 수 있도록 조건 저장
req = starbucks_name['ICED/HOT'] == "ICED"
## loc 이용하여 req 조건만 추출할 수 있도록 control
df_starbucks = starbucks_name.loc[req,:]
df_starbucks
# 기존 인덱스 초기화 -> 핸들링이 쉬울 수 있도록
# https://bjy2.tistory.com/184
df_starbucks_idrs = df_starbucks.reset_index(drop=True)
폴더 이름 자동 생성
그 후 폴더 이름 자동 생성을 위해 자연어 처리의 정규표현식을 이용하여 메뉴의 영어 이름 내 공백을 _로 변환하였습니다.
import re # 정규표현식 모듈 re
# df_starbucks_idrs["name_en"]# https://nachwon.github.io/regular-expressions/
r = re.compile("\s")
for i in range(len(df_starbucks_idrs)):
df_starbucks_idrs["name_en"][i] = r.sub("_", df_starbucks_idrs["name_en"][i])
df_starbucks_idrs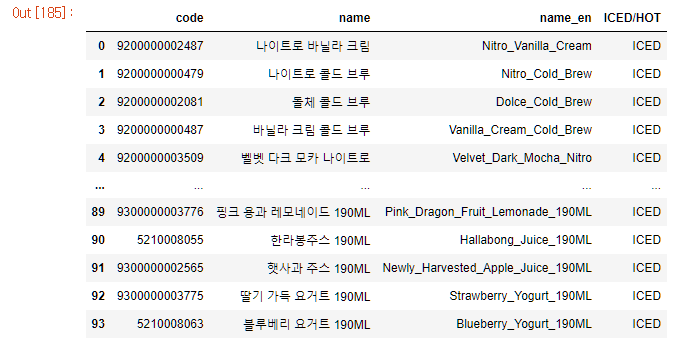
폴더 자동 생성 및 네이버 이미지 자동 크롤링
import os # 주피터 노트북 내의 여러 가지 operating System 제어 모듈
import shutil
os.getcwd() # 현재 경로 확인
※ 폴더 관리 및 폴더 자동 생성
해당 커널 시작 시마다 파일 및 폴더들이 중복되는 것을 방지하기 위해 대분류인 image 폴더를 일괄 control 해주는 작업을 해줄 것입니다.
# 만약 image 폴더가 삭제된다면 삭제 후 image 폴더를 새로 만들어주고
try:
shutil.rmtree("C:/Users/wodms/Jupyter_python/naver_crawling/image")
os.mkdir("C:/Users/wodms/Jupyter_python/naver_crawling/image")
# 그렇지 않다면 image 폴더가 없으므로 새로 만들어주기만 하자
except:
os.mkdir("C:/Users/wodms/Jupyter_python/naver_crawling/image")
※ 네이버 이미지 자동 크롤링
// 코드 안에 주석으로 설명을 달아놓았으니 참고해주세요~!
for i in range(len(df_starbucks_idrs)):
folder_name = df_starbucks_idrs["name_en"][i]
folder_route = "C:/Users/wodms/Jupyter_python/naver_crawling/image/" + folder_name
os.mkdir(folder_route) # 폴더 생성
# 이미지 크롤링 시작
driver = webdriver.Chrome() # 크롬 드라이버 열기
driver.get("https://search.naver.com/search.naver?where=image&sm=stb_nmr&")
element = driver.find_element("id", "nx_query")
# 검색어 입력 시 기존 이름 맨 앞에 스타벅스가 들어가있는 것을 방지하기 위함
r = re.search(r"^스타벅스", df_starbucks_idrs["name"][i]) # '스타벅스'로 시작하니?
# 위의 조건과 맞지 않으면 r 객체는 값이 없게 됨. 즉, None 값 가진다
if (r == None) == True:
pass
else:
df_starbucks_idrs["name"][i] = df_starbucks_idrs["name"][i].replace('스타벅스', '')
print(df_starbucks_idrs["name"][i])
# 검색 시 '스타벅스 메뉴 이름' 으로 입력하기 위해서
# ex) 스타벅스 바닐라 크림 콜드브루
search_keyword = "스타벅스 " + df_starbucks_idrs["name"][i]
element.send_keys(search_keyword)
element.submit()
# 스크롤링 반복할 횟수 지정
for j in range(1, 2):
# 웹창 클릭 후 END키 누르는 동작
# 브라우저 아무데서나 END키를 누른다고해서 페이지가 내려가지 않음
# body 활성화한 후 스크롤 동작
driver.find_element("xpath", "//body").send_keys(Keys.END)
# 이미지가 로드되는 속도를 10초로 설정
# 로드가 되지 않은 상태에서 저장하게 되면 No image로 뜨게 됨
time.sleep(10)
time.sleep(5) # 네트워크 속도를 위해 5초간 sleep 걸기
# 크롬 브라우저에서 현재 불러온 소스 코드를 가져옴
html = driver.page_source
soup = BeautifulSoup(html, "lxml")
def fetch_list_url():
# 이미지를 url이 있는 img 태그의 img 클래스로 간다
params = []
imgList = soup.find_all("img", class_="_image _listImage")
for im in imgList:
# 불러오지 못하는 이미지의 경로는 data-lazy-src에 있으므로
# try와 except 이용하여 둘 중에 하나로 불러오는 조건문 달기 !!
# 여기가 매우 중요함
try:
# data-lazy-src 참고한 블로그
# https://ongbike.tistory.com/151
params.append(im["data-lazy-src"])
except:
params.append(im["src"])
return params
def fetch_detail_url():
params = fetch_list_url()
a = 1
# 이미지 저장할 폴더 경로 지정
folder_route_final = folder_route + "/"
for p in params:
# 다운받을 폴더경로 입력
urllib.request.urlretrieve(p, folder_route_final + search_keyword + str(a) + ".jpg")
a += 1
fetch_detail_url()
# 브라우저 창 닫기
driver.quit()여러분 어떠세요~? 할만 하신가요?!?! 어렵죠ㅜㅜ저도 아직 어려운게 아주 많아요,,그래도 우리 모두 코딩 많이 해보면서 실력을 쌓아 보자구요~!!! 데이터 꿈나무들 파이팅!!

'Activity > 데이터 청년 캠퍼스' 카테고리의 다른 글
| [데이터 청년 캠퍼스] CNN의 ResNet50 모델로 스타벅스 음료 이미지 분류 모델 구현 with Python (0) | 2022.12.25 |
|---|---|
| [데이터 청년 캠퍼스] CNN을 이용한 모델링(VGG16 모델) / 스타벅스 이미지 분류 모델 (2) | 2022.12.24 |
| [데이터 청년 캠퍼스] 딥러닝 VGG16 모델 구현 이미지 전처리 with Python (0) | 2022.12.23 |
| [데이터 청년 캠퍼스] 구글 이미지 자동 스크롤 웹크롤링 with Python (4) | 2022.09.29 |
| [데이터 청년 캠퍼스] Python 스타벅스 메뉴 영양성분 크롤링 (2) | 2022.09.17 |


