
데이터 꿈나무
[데이터 청년 캠퍼스] Python 스타벅스 메뉴 영양성분 크롤링 본문
안녕하세요:) 첫번째 게시물은 크롤링으로 시작하려고 합니다.
데이터 청년 캠퍼스라는 대외활동 과정을 통해서 카페 메뉴 및 영양성분을 크롤링 해보는 경험을 가졌었는데요, 프로젝트 활동을 하면서 팀원들과 같이 작성한 코드를 공유해 드리려고 해요..! 중간 중간에 설명도 달아놓았으니 도움이 되셨으면 좋겠습니다!!
우선 크롤링을 하기 위한 모듈을 불러와야 합니다.
해당 모듈이 없을 시에 오류가 뜨게 되는데, 이는 아래의 주석과 같이 'pip install 모듈이름' 을 해주어 모듈을 설치해주면 됩니다.
# pip install selenium
from selenium import webdriver
from bs4 import BeautifulSoup
from pprint import pprint다음으로는 webdriver를 실행시켜주어야 합니다. webdriver를 실행시켜주려면 Chrome의 webdriver를 설치해준 후 해당 코드를 작성하는 파일에 webdriver가 있어야 실행이 됩니다.
저는 스타벅스의 메뉴 및 영양성분이 있는 홈페이지 주소를 가져와서 webdriver를 실행시켜주었습니다.
# webdriver 실행
browser = webdriver.Chrome()
browser.get("https://www.starbucks.co.kr/menu/drink_list.do")
page_source
page_source는 단순히 driver가 위치한 웹페이지의 소스 코드를 얻을 수 있는 기능입니다.
BeautifulSoup
BeautifulSoup은 텍스트 형태의 html이며 텍스트 형태의 데이터에서 원하는 html 태그를 추출하는 것을 쉽게 할 수 있도록 도와줍니다. 생성된 soup객체를 사용하면 class에 정의된 메서드를 사용할 수 있습니다.
그리고 soup객체에 있는 select메서드를 이용하여 html에서 특정 태그값만 찾아주었습니다.
저는 스타벅스의 음료 메뉴를 모두 크롤링하기 위해 해당 태그를 찾아주었습니다.
해당 코드의 결과는 아래와 같습니다.
※ 태그 확인 방법
1. F12키를 누른다.
2. 원하는 위치에 커서를 놓고 우측 마우스를 누른 후 맨 밑에 있는 검사키를 누른다. (원하는 태그를 수집할 수 있음)
# html source 추출
html = browser.page_source
# html parsing
soup = BeautifulSoup(html, 'html.parser')
# 원하는 항목 데이터 추출
products = soup.select('.product_list dd a')
#pprint(products)

그 후 제품 코드와 제품 이름만 따로 불러와서 prod_cd에 저장해주었습니다.
prod속성 값과 'img태그의 'alt'값을 추출하였습니다.
# 코드, 제품 이름
prod_cd = [[product['prod'], product.find('img')['alt']] for product in products]
pprint(prod_cd)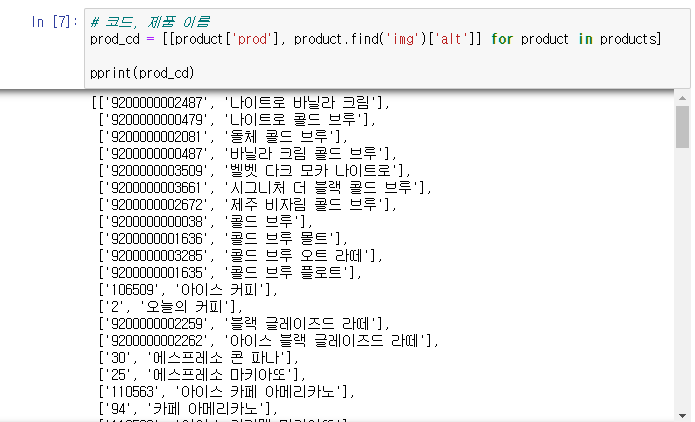
다음으로 제품 코드로 각 상세 페이지에서 영양정보를 스크랩해 주었습니다.
위에서 특정 태그를 알 수 있는 방법을 알려드린 것과 같이 각 영양성분 위에 커서를 둔 후 검사키를 눌러,
각각의 칼로리, 지방, 단백질, 나트륨, 카페인 등 영양성분을 크롤링하여 result에 넣어주었습니다.
이 과정에서는 모든 음료 메뉴 영양성분을 크롤링해야 하는 거라 시간이 좀 걸리네요ㅎㅎ
저는 크롤링 기다리면서 유튜브를 보거나 음악을 듣거나 한답니다..!
마냥 기다리는 것은 지루하니까요~~

※ time.sleep(3)을 해주는 이유?
크롤링하는 데이터 양이 많다보면 특정 사이트에서 IP 차단 당하는 경우가 있습니다. 그러면 한동한 사이트 접속이 불가능해지기 때문에 이런 상황을 막기 위해 쓰는 방법 중 하나입니다.
import time
# 결과 값을 담을 빈 리스트 생성
result = []
for prod in prod_cd:
container = dict()
cd = prod[0]
name = prod[1]
browser.get(f"https://www.starbucks.co.kr/menu/drink_view.do?product_cd={cd}")
html = browser.page_source
soup = BeautifulSoup(html, 'html.parser')
# 용량
volume = soup.select_one('.product_info_head #product_info01').get_text()
# 제품 영양 정보
cateL = soup.select_one('.smap .cate').get_text()
kcal = soup.select_one('.product_info_content .kcal dd').get_text()
sat_FAT = soup.select_one('.product_info_content .sat_FAT dd').get_text()
protein = soup.select_one('.product_info_content .protein dd').get_text()
fat = soup.select_one('.product_info_content .fat dd').get_text()
trans_FAT = soup.select_one('.product_info_content .trans_FAT dd').get_text()
sodium = soup.select_one('.product_info_content .sodium dd').get_text()
sugars = soup.select_one('.product_info_content .sugars dd').get_text()
caffeine = soup.select_one('.product_info_content .caffeine dd').get_text()
cholesterol = soup.select_one('.product_info_content .cholesterol dd').get_text()
container['분류'] = cateL
container['1회 제공량'] = volume
container['메뉴'] = name
container['칼로리(kcal)'] = kcal
container['당류(g)'] = sugars
container['단백질(g)'] = protein
container['나트륨(mg)'] = sodium
container['포화지방(g)'] = sat_FAT
container['카페인(mg)'] = caffeine
result.append(container)
# 트래픽 조절을 위해 3초간 sleep
time.sleep(3)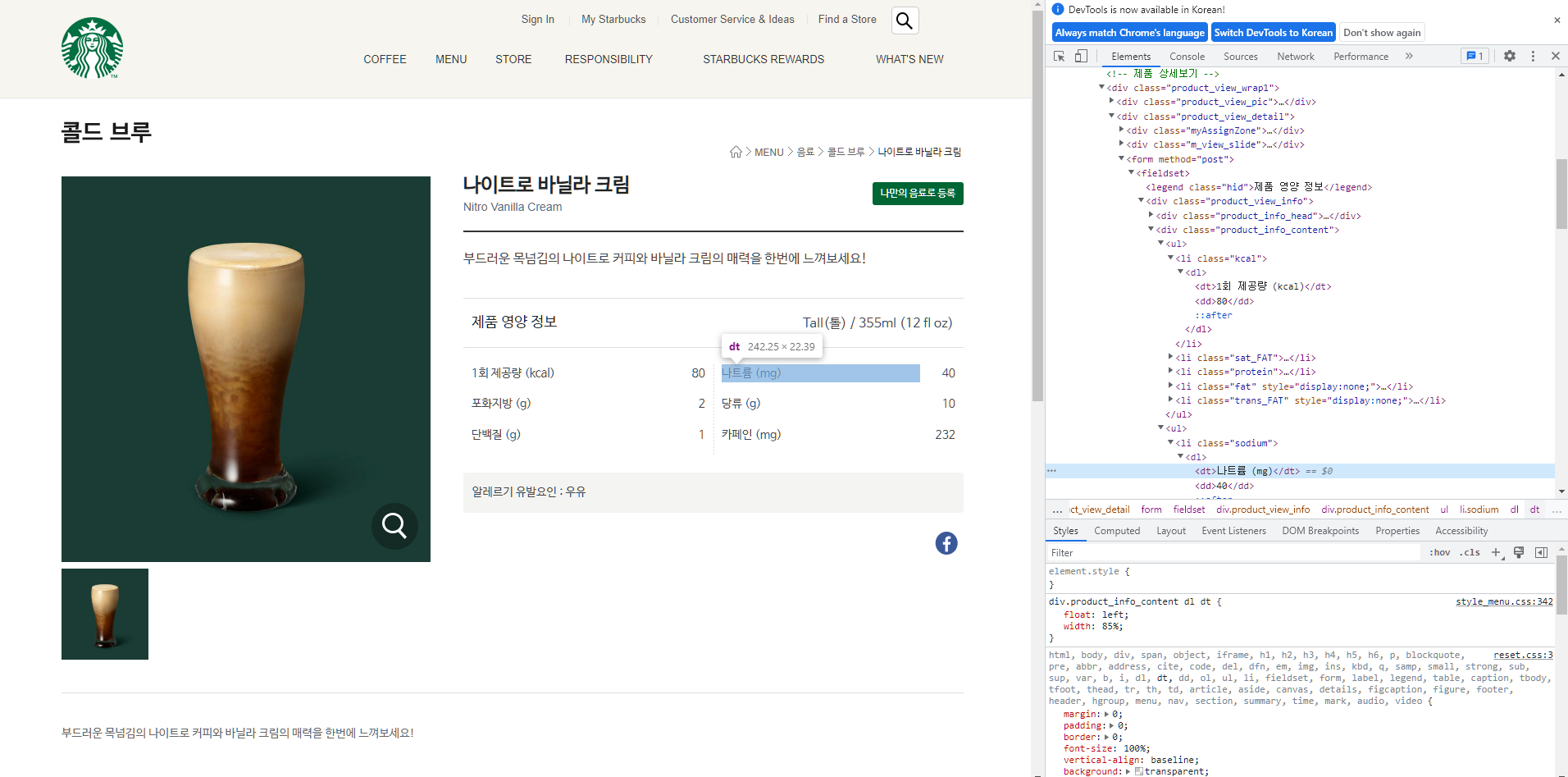
그 후 result에 원하는 정보가 다 들어갔는지 확인하기 위해 pprint를 해주었습니다.
※ pprint?
pprint는 예쁘게 출력을 해주는 모듈입니다. 파이썬에서 print문을 사용하면 기본적인 출력을 할 수 있지만 많은 양의 데이터를 다룰 때, 이를 테면 중첩된 리스트나 딕셔너리, API요청 결과, JSON을 print문으로 출력하게 되면 그 결과를 직접 눈으로 읽고 확인하기가 쉽지 않습니다. 이럴 때 유용한게 바로 pprint입니다.
지금까지는 별 생각없이 썼는데 이름이 pprint인 이유가 말 그대로 pretty print를 줄여서 pprint라고 하네요?! 너무 귀엽지 않나요ㅎㅎ
이렇게 글로만 써서는 print와 pprint의 차이가 무엇인지 감이 안 오실텐데요, 위에서 크롤링한 것을 예시로 출력했을 때 어떤 차이가 있는지 보여드리겠습니다!


어떠세요~~?? 차이가 보이시나요? 확실히 보기 편하게 출력되는 것을 확인할 수 있죠?

마지막으로 수집한 음료 영양성분 정보를 csv파일로 저장해줍니다.
import pandas as pd
# DataFrame으로 변환
df = pd.DataFrame(result)
# csv 파일로 저장
df.to_csv('./starbucks.csv', index = False, encoding="utf-8-sig")
# 데이터 확인
df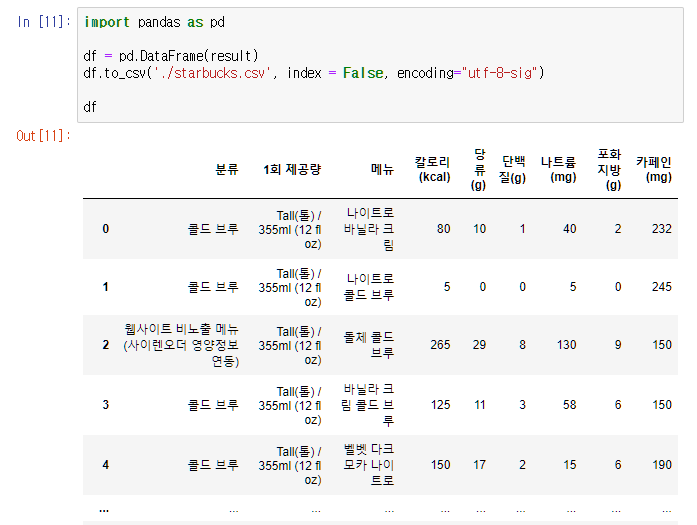
그리고 브라우저를 닫아주면 끝!!
# 브라우저 닫기
browser.quit()
'Activity > 데이터 청년 캠퍼스' 카테고리의 다른 글
| [데이터 청년 캠퍼스] CNN의 ResNet50 모델로 스타벅스 음료 이미지 분류 모델 구현 with Python (0) | 2022.12.25 |
|---|---|
| [데이터 청년 캠퍼스] CNN을 이용한 모델링(VGG16 모델) / 스타벅스 이미지 분류 모델 (2) | 2022.12.24 |
| [데이터 청년 캠퍼스] 딥러닝 VGG16 모델 구현 이미지 전처리 with Python (0) | 2022.12.23 |
| [데이터 청년 캠퍼스] 구글 이미지 자동 스크롤 웹크롤링 with Python (4) | 2022.09.29 |
| [데이터 청년 캠퍼스] 네이버 자동 스크롤 이미지 크롤링 with 파이썬(Python) (2) | 2022.09.25 |


